
[�n�̺���]�������n��������һ���Ĕ��������ھ��㷨���A�Ĺ��̎�������Ҍ��`�������ھ�ƽ�_���ĿӖ����ϵ�y���v�┵���ʂ䡢������ģ���ھ�ģ�ͽ������������c�ھ��㷨�����ژI��ģ���У��Y��������Hadoop�cSpark������ƽ�_�ܘ������F�ĿӖ���� ...
| ���r�g���c�� | 2021��5��28-31�� �ɶ� ����9:00-12:00������14:00-17:00 |
|
| ����Ӗ�v���� | ���ώ��� | |
| �����ӌ��� | 1.�����������_�l���̎���2.�������Ŀ��Ҏ����ԃ�����ˆT��3.�������Ŀ��IT�Ŀ�߹��ˆT��4.�������c�ھ�̎���㷨���ù��̎���5.��������Ⱥ�\�S���̎���6.�������Ŀ����ǰ���ۺ��g֧�ַ����ˆT�� | |
| �������M�á� | ��7800Ԫ/�� ������Ӗ�M���Y���M����ԇ�M��A��C���M�� ��Ҫס�ތW�TՈ��ǰ֪ͨ���ɽyһ���ţ��M�������� | |
| �����սM���� | ɭ����Ӗ�W��m.gzlkec.com�����V��������I������ԃ����˾ | |
| ����ԃ�Ԓ�� | 020-34071250��020-34071978����ǰ���������ܸ������ݣ� | |
| �� ϵ �ˡ� | ����������С�㣻13378458028��18924110388�����ɼ��ţ� | |
| ���ھ� QQ �� | 568499978 |  �n�V���d �n�V���d  |
| ����ܰ��ʾ�� | ���n�̿����M����I�Ȳ���Ӗ���gӭ����A�s�� | |
����ģ�c�����ھ��g�ѽ��ؑ��õ����d���W��I��������̄վWվ���������桢�罻�Wվ�����W�V������ṩ�̵ȣ����y�н����Cȯ��I������\�I���ИI���o�@Щ�ИI������һ���Ĕ����rֵ��ֵ���á�
�����n��������һ���Ĕ��������ھ��㷨���A�Ĺ��̎�������Ҍ��`�������ھ�ƽ�_���ĿӖ����ϵ�y���v�┵���ʂ䡢������ģ���ھ�ģ�ͽ������������c�ھ��㷨�����ژI��ģ���У��Y��������Hadoop�cSpark������ƽ�_�ܘ������F�ĿӖ����
�Y�ϘI��ʹ����V����������ƽ�_���g�����c�������ڴ������㷨�cBI���g���ã���������㷨������㷨���A�y�����㷨�����]����ģ�͵��ژI���еČ��`���ã��������v���o���Ĕ����������F�ɂ���������־���������ھ�ϵ�y���Լ���̣�����ݣ����]ϵ�y���档
���n�̻����Č��`�h����Linux��Ⱥ��JDK1.8�� Hadoop 2.7.*��Spark 2.1.*��
�W�T��Ҫ�ʂ����X�����i7����������CPU��8GB�����σȴ棬Ӳ�P���g�A��50GB�������Ƅ�Ӳ�P���������Ĵ�����ƽ�_����ه��ܛ��������ه��ȣ��v���ѽ���ǰ������̓�M�C�R��VMware�R���W�T�����v���IJ����΄��M�Ќ��`��
���n�̲��ü��gԭ���c�Ŀ������Y�ϵķ�ʽ�M�н̌W�����v��ԭ�����^���У����匍�H��ϵ�y���������n���v��Ҳ���Ĝʂ�Č��H�đ��ð������W�T����Ӗ����
��ӖĿ��
1.���n���W�T������մ�ƽ�_���g�ܘ����������Ļ�����Փ���C���W���ij����㷨�������������Ĵ������cBI�̘I���ܷ�����Q�������Լ����������������桢�V��������]����̔������������ڿ͑���������đ��ð�����
2.���n�̏��{�����Ĵ������ھ��㷨���g�đ��úͷ���ƽ�_�Č�ʩ���W�T���������Ļ��ڴ�Hadoop��Spark�Ĵ�����ƽ�_�ܘ��͌��H���ã����ýY�ό��H�����aϵ�y�����M�н̌W�����ջ���Hadoop��spark��ƽ�_�Ĕ����ھ�͔����}��ֲ�ʽϵ�yƽ�_���ã��Լ��̘I���_Դ�Ĕ��������aƷ����Hadoopƽ�_�γɴ�����ƽ�_�đ�����������
3.�W�T���ճ�Ҋ�ęC���W���㷨�������v��I�����Ĵ������ھ��cBIƽ�_�Č��`���ã����Կ͑�����ϵ�y����־������������]ϵ�y�鰸���������õĔ����ھ��g�M�Б��ý̌W��
��Ӗ��ɫ
�������n+ ������Ӗ��+ ������ԃӑՓ����3��
���f�����v�����ṩ̓�M�C�R����Hadoop��Spark��ϵ�y��ǰ������̓�M�C�У������ھ�ƽ�_������Hadoop�cSpark֮�ϣ��W�T�Ԏ��Pӛ�����\��̓�M�C��������ͬ�ӵ��R�Ӷ��_̓�M�C��������Ⱥ���R�����ǰ�o�W�T��
Ԕ����V�c��Ӗ����
�ɂ��������Ŀ�΄պ͌��`���������c��
1.��־������ģ�c��־�ھ��Ŀ���`
a)Hadoop��Spark�����Y��ELK���g������־����ϵ�y����־�����}��
b)���W����־����ϵ�y�Ŀ
2.���]ϵ�y�Ŀ���`
a)�Ӱ���������c���Ի����]�P�����Ŀ
b)���ُ��@�����Ŀ
Hadoop��Spark���ɽY��Oryx�ֲ�ʽ��Ⱥ�ڂ��Ի����]�;��ʠI�N�Ŀ��
�Ŀ���A���Բ��E؞�����������Ӗ�^���У���������������Ŀ��ԭ��
��Ӗ���ݰ������£�
|
�r�g |
������Ҫ |
���nԔ������ |
���`Ӗ�� |
|
��һ�� |
�I�������Ĕ����}�칤�ߺʹ������ھ� |
|
���Ô����}�칤��Hadoop Hive��SparkSQL ���������ھ�Hadoop Mahout��Spark MLlib |
|
�������ھ��Ŀ�Ĕ������ɲ���Ӗ�� |
|
�Ŀ���������dETL��Hadoop Hive�����}�첢������Sģ�� | |
|
����Hadoop�Ĵ��͔����}�����ƽ�_��HIVE�����}�켯Ⱥ�Ķ�S������ģ���Ì��` |
|
����HIVE�������͔����}���Ŀ�IJ���Ӗ�����` | |
|
Spark�������ھ�ƽ�_���`����Ӗ�� |
|
| |
|
�ڶ��� |
�������ģ�c�ھ��㷨�Č��Fԭ���ͼ��g���� |
|
����Spark MLlib�ľ�����㷨�����F��־�������е��Ñ���� |
|
�������ģ�c�ھ��㷨�Č��Fԭ���ͼ��g���� |
|
����Spark MLlib�ķ�����㷨ģ���c���ò��� | |
|
�P������ģ�c�ھ��㷨�Č��Fԭ���ͼ��g���� |
|
����Spark MLlib���P�������� | |
|
������ |
���]�����ھ�ģ���c�㷨���g���� |
|
���]�������F���E�c���������c�� |
|
�ؚw����ģ���c�A�y�㷨 |
|
�ؚw�����A�y�������� | |
|
�D�Pϵ��ģ�c�����ھ���朽ӷ������罻�������� |
|
�D�����ķ����ھ���������F�����������罻�W�j��ģ�c�Pϵ���� | |
|
�W�j�c��ȌW���㷨ģ�ͼ��䑪�Ì��` |
|
����Spark��TensorFlow�W�j��ȌW���쌍�F�ı��c�DƬ�����ھ� | |
|
�Ŀ���` |
|
�Ŀ��������Ԕ���Č��ָ���փ����v���ṩ | |
|
|
��Ӗ���Y |
|
ӑՓ���� |
|
������ |
�W�T��ԇ�c�I�罻�� | ||
���Y����
���ώ�������������ң������Y���Spark��Hadoop���g���ҡ�̓�M�����ң���HDFS��MapReduce��HBase��Hive��Mahout��Storm��spark��openTSDB��Hadoop���Bϵ�y�еļ��g�M���˶����������о�������Ҫ�����@Щ���g�ڴ����Č��H�Ŀ�еõ��V���đ��ã������Hadoop�_�l���\�S����e�����S�����Ŀ��ʩ��������Ҫ���͵��Ŀ�У�ij��ż��F�W�j�������Ї��Ƅ�ijʡ�Ƅӹ�˾Ո�~��ϵ�y��ijʡ�Ƅ�Ԕ�Ό��r��ԃϵ�y���Ї��y������Ʊ��Ԕ��ƽ�_��ij�����y�д�ӛ�ϵ�y��ij����ͨ���\�I��ȫ���Ñ��ϾWӛ䛡�ijʡ��ͨ���T�`��ϵ�y��ij�^���t���������Ŀ�����W������������(DAAS)�͘����Α���(Web Game Daas)ƽ�_�Ŀ�ȡ�
�C�l�C��
A����I����Ϣ����ȫ���W�j�c��Ϣ���g��ԇ���������C�l��-��Python�����g�C������ԓ�C�������錣�I���g�ˆT�I�������˵��C����
B����I����Ϣ���������c��ԇ�����C�l��-�����������C������ԓ�C���ǹٷ�Ψһ�J�C�C����ͬ�rҲ�����И˼ӷ֡���λ������н�����������J�C���C����
ע��Ո�W�T�ʂ���Ӳ���1���������C��ӡ��һ�����k���C��ʹ�á�
��ͬ�C�����M���f����
7800Ԫ/�ˣ�����Ӗ�M���Y���M����ԇ�M��A��C���M��
9800Ԫ/�ˣ�����Ӗ�M���Y���M����ԇ�M��B��C���M��
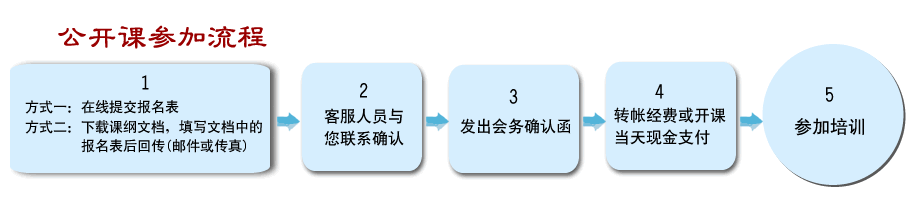
 �n�V���d
�n�V���d 

 ���T�c����
���T�c����